| ClusterReplica Standard Edition v2.0 |
|
Let's take a look at the first situation:
The data structure is on the same system as the network server
ClusterReplica will be installed on the network server systems.
Because ClusterReplica also includes the failover/failback features, the network server can use it for server availability functions. To use ClusterReplica, you need to set up two identical servers and, with ClusterReplica running on both systems, you configure one as the active server, the other the Standby server.
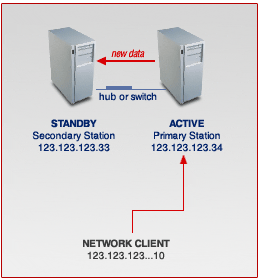
Your new network server can be seen as the systems in the brown box of following picture. Here the two systems function together as the network server now : to network clients, the server IP will always be the one of the active server system. Data replication is only from the ACTIVE server to the STANDBY server when both systems are functioning normally.
|
 |
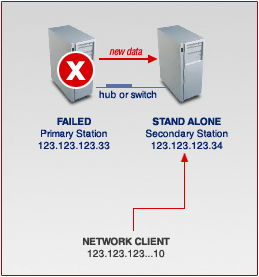
- Above picture shows how the cluster server works when both ACTIVE and STANDBY servers are running normally.
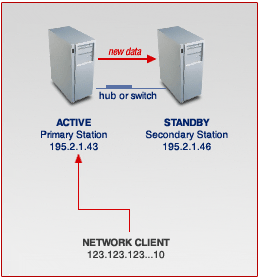
- The next picture shows the situation when the ACTIVE server is down.
Your network server is now in Failover state: Now, the Standby server is activated and all of network service requests and newly entered data are going to the STANDBY system. To the network clients, however, their network access IP remains that of the ACTIVE servers - nothing is changed.
|
 |
- After five hours of hard work, you fixed the problem on the ACTIVE server, and reconnected it to the STANDBY server.
Before activating the ACTIVE server, you are facing the choice of:
- replacing the data on the ACTIVE server with the updated data now on the STANDBY server
- or not replacing the data
With this question settled, the network server will be back running normally again.
|
|
The second situation:
The data structure is not on the same system of the network server, but running on a separate server system
ClusterReplica will be installed directly on the database servers. Now, ClusterReplica's failover/failback functions will take care only the database servers, and will have no effect on the network server.
Your new database server now includes an active server and a standby server. The systems included in the brown box is functioning together as your new database server now : Notice that the data replication is only from the ACTIVE server to the STANDBY server when both systems are functioning normally. |
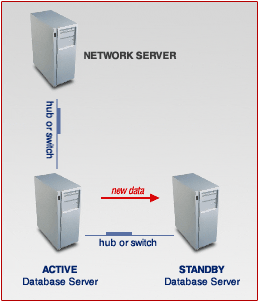 |
- Above picture shows how the cluster server works when both ACTIVE and STANDBY servers are running normally.
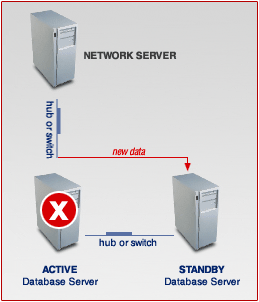
- The next picture shows the situation when the ACTIVE server is down.
Your network server is now in Failover state: Notice now all new data coming from the network server will be stored directly on the STANDBY server.
|
 |
- After five hours of hard work, you fixed the problem on the ACTIVE server, and reconnected it to the STANDBY server.
Before activating the ACTIVE server, you are facing the choice of:
- replacing the data on the ACTIVE server with the updated data now on the STANDBY server
- or not replacing the data
With this question settled, the network server will be back running normally again.
|
| |
| System and Service Level Failover |
|
Failover is the process specifically associated to cluster systems. Typically it means when the Primary station of a cluster system dies, the Secondary station will be activated to take over the active duty of the Primary station. This feature supports the high availability of the cluster server.
XLink's ClusterReplica Standard edition binds two Windows systems together as the cluster server, which is best applicable for web server and file servers. It will monitor the systems in the cluster system and the pre-defined services to determine if the cluster system is in the condition that a failover should be activated.
Failover conditions
ClusterReplica makes decisions on activation of failover on three types of conditions:
- System failover - This happens when the entire Primary system is down
- Service level failover - When any one of the monitored services is not functioning normally
|
Detailed explanations of these conditions are listed below.
- System Level Failover
The first picture (1) below shows a normal working situation of the cluster server. When the Primary station fails, the Secondary Station will become the Primary station and work in STAND ALONE mode as seen in picture (2).
- Service Level Failover
Failover will take place when one of the services fails to function normally. In this situation, both clustered systems will be running. However, their roles of ACTIVE and STANDBY will be switched automatically.
NOTE: when the ACTIVE station is changed to become the STANDBY Station, you know there is a service or application on that system failed to function normally. You should exam the Secondary station and fix the problem without delay. Resetting the cluster system is also important.
Here are some pictures to provide a general description of Failover (1)(2) and Failback (3)(4).
|
|
| |
| Realtime File Replication |
|
File Replication is one of the key features of ClusterReplica Standard edition. The main purpose of File Replication is to copy all current files on the ACTIVE station of a clustered system to the STANDBY station for disaster recovery. ClusterReplica Standard edition is capable of replicating all types of files including database files at real time. Open and locked files can also be replicated. |
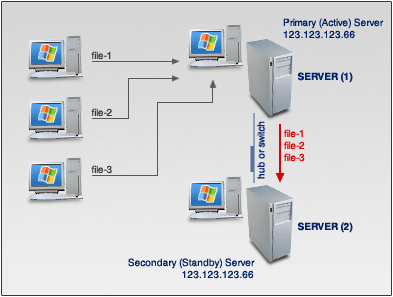 |
This is an example of how ClusterReplica works.
All of the new files received by the ACTIVE station will be copied to the STANDBY station at real time.
When the files to be replicated require a application or service to access, these applications and services must also be added to the monitored list of file replication for Failover processing. |
|
| |
| Service Level Failover |
|
The Registry Replication functionality meets the needs of some server systems which require certain dynamically changed key definitions of registry matched on the Secondary server for a successful failover.
When to use "Registry Replication"
Use Registry Replication only when it is absolutely necessary. Because the registry controls the operation of the entire system, it is recommended that you don't change any thing in it unless you know precisely what you are doing.
Warning: Do not replicate the entire registry - replicate only the keys that are needed. |
| |
| Service Level Failover |
|
-
When to use Failover Shared Folder
Failover Share Folder is designed for network drive sharing on the cluster server.
If you have drives or folders shared out for network usage (through Windows "map network drive"), you will need to setup this configuration to ensure the drives or folders to be properly shared out on the Secondary server when the Failover occurs.
- Typical applications of Failover Shared Folder
Web server and File server are the typical examples in need of shared folders. IT personnel may need to access the web site remotely for web page updating. Network clients of a file server may nee to get a shared folder for local use for high convenience and efficiency.
For these reasons, shared folders failover can guarantee non-interruption of works and no loss of data.
|
| |
|